The Institute for Protein Design is collaborating with NVIDIA to deliver the accelerations necessary for protein design pipelines to meet global grand challenges.


Nate Corley (left), Dr. Frank DiMaio (right), and the IPD Machine Learning team have been leading this collaboration to accelerate design tools with NVIDIA.
At the Institute for Protein Design we create new proteins, atom by atom on a computer, before we ever make them in the lab. For a long time, the hardest part was getting the basics to work at all. Today, many of those once-hard problems are largely solved: we can routinely design proteins that fold as intended and even stick to a chosen target.
So we have turned to a much harder set of problems. We call our long-term goal programmable matter; being able to decide what atoms go where, and what they do, on demand and at scale. In practice, that means moving from simple, static molecules to far more complicated and globally valuable products: custom enzymes that break down plastics, PFAS, and toxins; durable vaccines for diseases that have resisted them; hybrid protein-mineral materials; and powered molecular machines that can move and manipulate their environment. In the process of creating these genuinely difficult products, we are constantly learning what it takes to push the frontier.
Accelerating design leads to faster science and solutions
Our current design models put us in the ballpark of approximating a protein sequence with a desired function. Structural inference is the filter after design that evaluates if what we’ve modeled will be accurate in reality. Inference is where truly challenging design campaign progress piles up. Creating one enzyme, for example, can require running inference on millions of candidate designs to identify just a few suitable for real-world testing.
Accelerating inference allows the modelers at the IPD to filter significantly more and varied designs, creating more viable candidates for testing in the lab. They take what works and use that data to refine the next round of attempts. Cutting inference time allows us to bring more designs forward for testing and push the frontier of what is possible in design faster, delivering solutions for human health, environmental resilience, and materials science sooner.
A first step with NVIDIA
To start chipping away at this limitation, we have collaborated with NVIDIA, whose teams build open source software and models to accelerate discovery across healthcare, science, and many other industries as part of the NVIDIA BioNeMo Agent Toolkit. Working together, we have ongoing joint research efforts on model development and accelerated computing applications, including the integration and early testers of their digital biology tools, including NVIDIA cuEquivariance and NVIDIA TensorRT to our RF3 pipeline. IPD brings the frontier design pipeline, representative benchmark workloads, and the experimental validation needed for protein design. NVIDIA brings expertise in GPU kernels, inference optimization, and software stack that enables crucial acceleration that helps drive IPD’s R&D.
Measured end-to-end on a 256-residue protein (Figure 1), these tools cut RF3’s prediction time from 5.8 seconds to 2.5 seconds, more than half. cuEquivariance speeds up the geometry-aware calculations at the core of the network, and TensorRT optimizes how the model runs on the hardware. Other GPU-accelerated tools, like a faster version of the sequence-search step (MMseqs2-GPU), have similarly helped shorten each design-and-test cycle.
This is just the start of our work together, but already a significant advance worth sharing with the field. We have only applied these optimizations to part of our overarching pipeline, and we are confident that significant accelerations are still in reach. The importance of this work is larger than a single software speedup. As design complexity increases, a key limitation will be compute availability. Speeding up our computational design process is not something model builders can do alone, and it is not something infrastructure providers can do without us.
So the path forward, as we see it, is for model builders—in academia and industry—and the people who design the infrastructure and open software to work hand-in-hand, and early. If the next generation of design models is shaped together with the systems it will run on, those models can be fast from the start rather than optimized years later. That is how we keep moving quickly enough to keep going — toward enzymes that clean up pollutants, materials for energy and electronics, biosensors, and new medicines—while keeping the tools that get us there open to the wider scientific community.
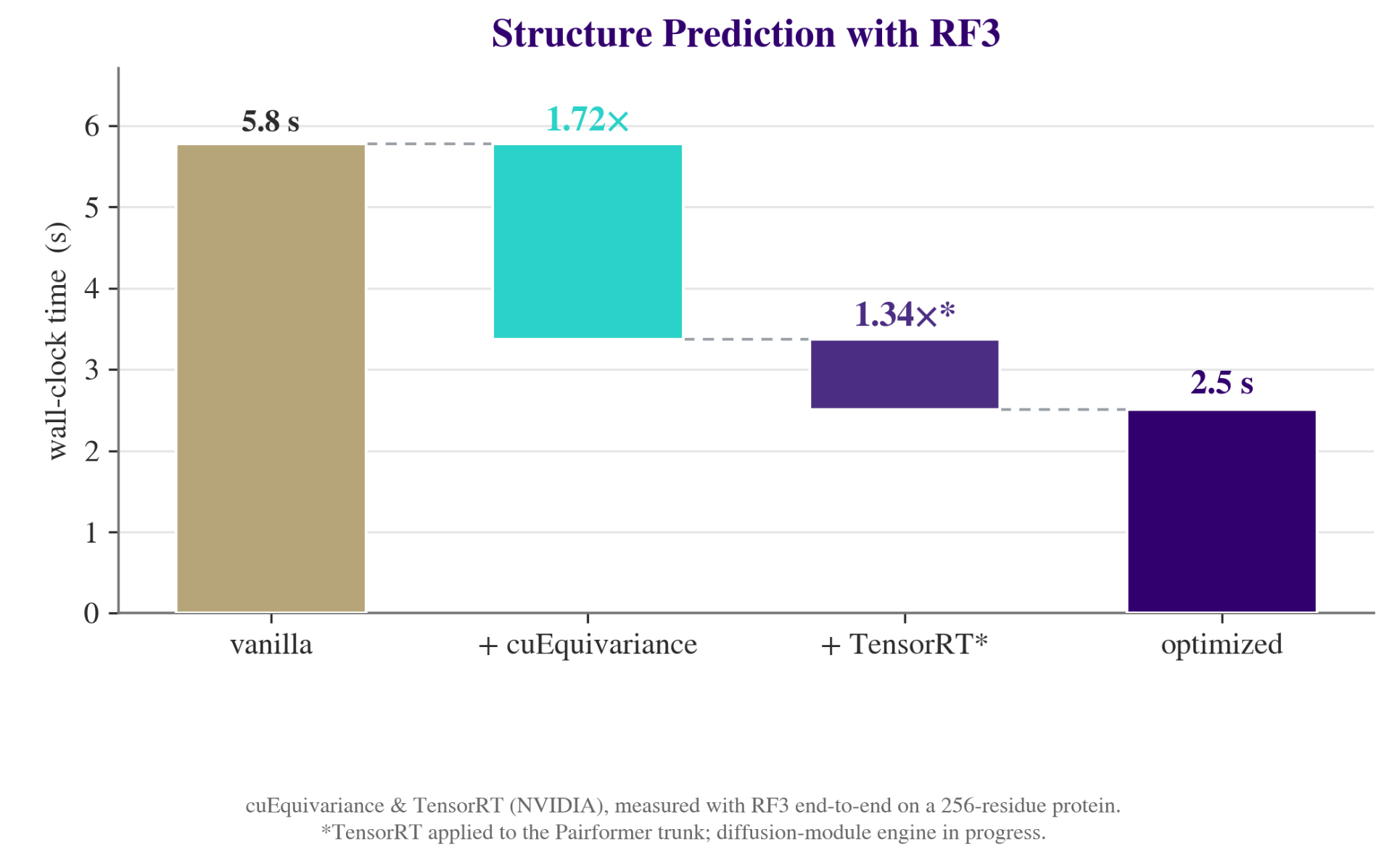
Figure 1: Wall-clock time for an end-to-end RF3 structure prediction on a 256-residue protein, before and after acceleration. cuEquivariance and TensorRT are NVIDIA software tools. TensorRT is currently applied to the Pairformer trunk; work on the diffusion module is ongoing.
Additional Information
This project was led by the Institute for Protein Design at UW Medicine.
This research was funded by the Howard Hughes Medical Institute.